FreeGPT: Scraping the Web Scrapers
I come across the Cloudflare bot protection quite a lot, especially when browsing on a VPN.
This project started out with me trying to bypass this detection, and ended with me making a free (for me) ChatGPT (and Claude, Deepseek, Gemini) API with no usage limits.
cloudflare bot protection
Cloudflare talks a big game, and many websites use their services (especially in the era of rampant web-scraping).
They collect lots of data about how you interact with a website to score how likely you are to be a bot, and if you cross a certain threshold, force you to solve a captcha. Their algorithm is constantly updated and (allegedly) learns over time to combat new evasion techniques in a classic cat-and-mouse game.
Some of the data they collect to evaluate your “bot-iness” is:
- Different timing delays during typing and mouse movement
- Your browser’s fingerprint
- Your IP address
- TLS fingerprinting
And so on.
These checks run on the target webpage (with Cloudflare-provided Javascript), and at request time using Cloudflare’s reverse proxies.
picking a target
I use the free version of ChatGPT quite a bit as a sort of snippet generator when coding in unfamiliar languages. Usually to make Javascript XSS payloads at work, but also when doing personal projects (who can tell me how to iterate through an object in insertion-order?). It also doesn’t require logging in, which simplifies the bot.
Naturally, chatgpt.com uses Cloudflare to prevent scraping. Target acquired.
a naive first try
Headless browsers libraries like Selenium, Puppeteer and Playwright are most commonly used by web-scrapers to pose as all the big browsers (Firefox, Safari, or Chrome). I picked Playwright to start with, writing the first naive version of the bot in Python in all of 50 lines.
After starting up, it went to chatgpt.com and tried to submit a chat.
Needless to say, baby’s first web-scraper did not bypass Cloudflare’s bot protection. What looked like signed requests (courtesy of Cloudflare) returned 403s. Time to move on.
a naive second try
There is a lot of literature about bypassing Cloudflare, webscraping is big business after all, and Cloudflare directly gets in the way.
However during development most of what I saw was outdated. If I can search for how to bypass bot protection, so can the engineers at Cloudflare. I tried a variety of these individual edits to the default Playwright instance, but of course nothing worked.
the fun bad solution
After getting fed up with Python Playwright, I decided to just brute force the automation using a Debian VM and a X11 automation tool (xdotool).
There are three parts to this version,
- The client (usually just used curl when testing) which communicates with the Golang server
- A Golang server which recieves the client request, running on the VM, it runs some xdotool commands to interact with a full-fat Firefox browser
- A Firefox extension that communicates with the Golang server about events (ex: page load, ChatGPT response created, etc.)
The flow goes like this:
- Client sends a POST request with their message to the Golang server on the VM
- The VM runs some xdotool commands to interact with a full-fat Firefox browser to navigate to chatgpt.com
- The extension communicates with the Golang server that the page was loaded
- Golang server runs some more xdotool commands to input the client’s message
- The extension waits for the response, and forwards it back to the Golang server
- Golang server finally responds to client with the ChatGPT output
I attached a small gif of the VM as it process a chat message below:
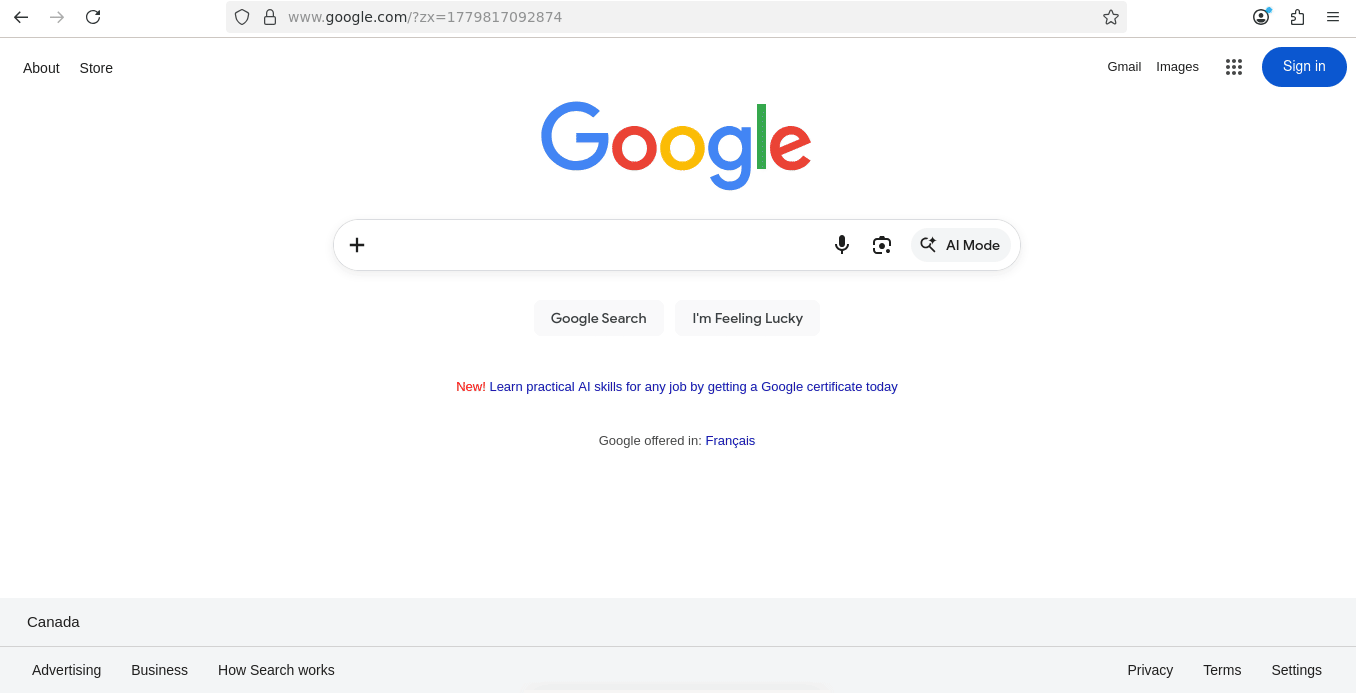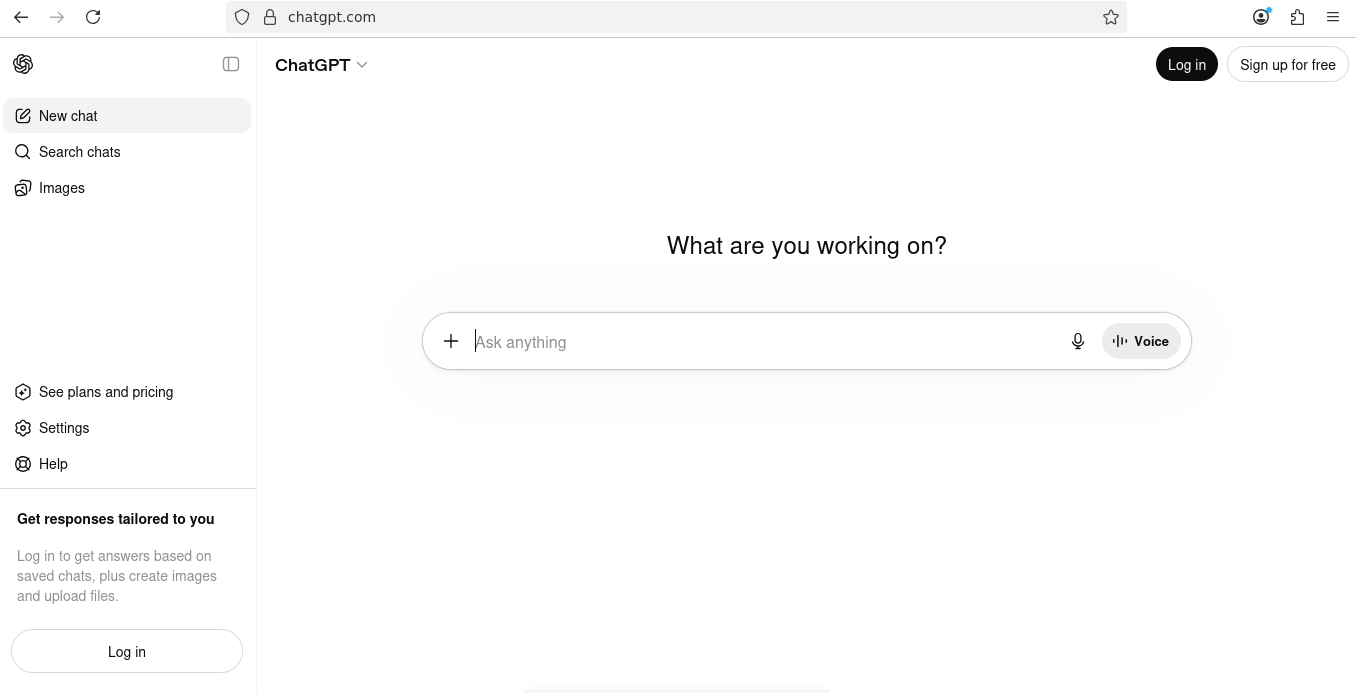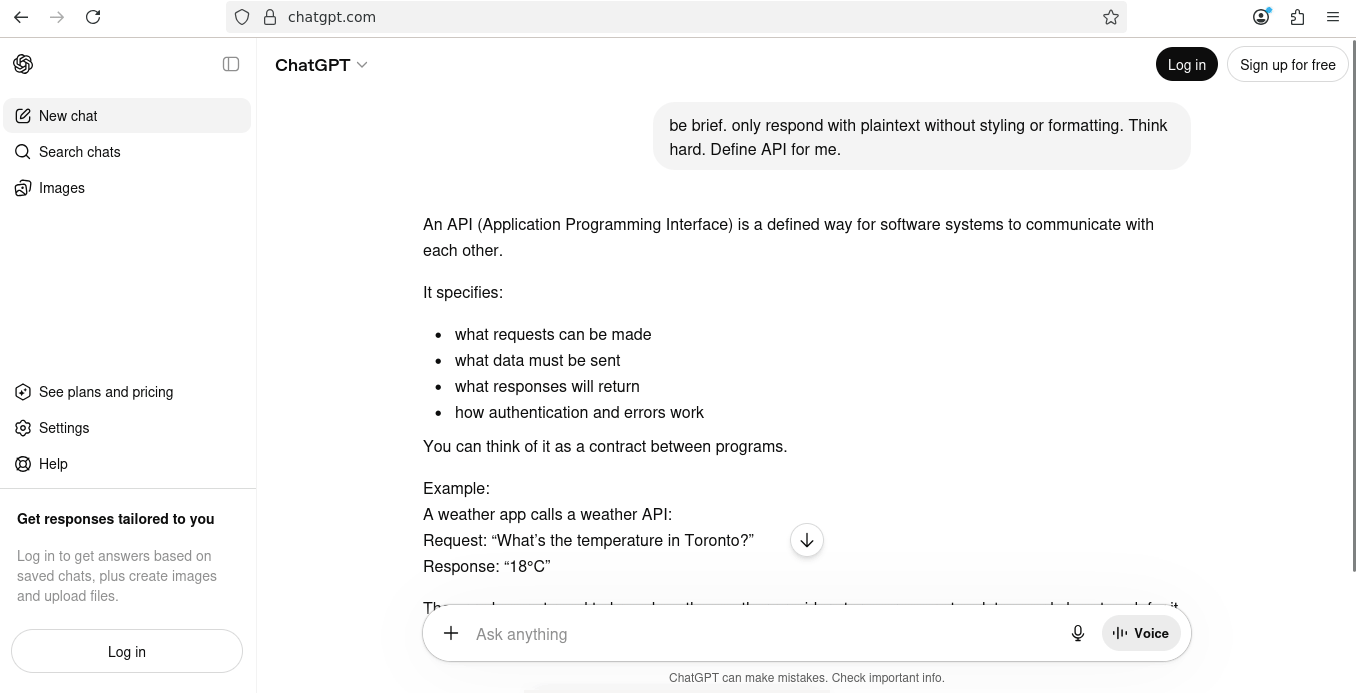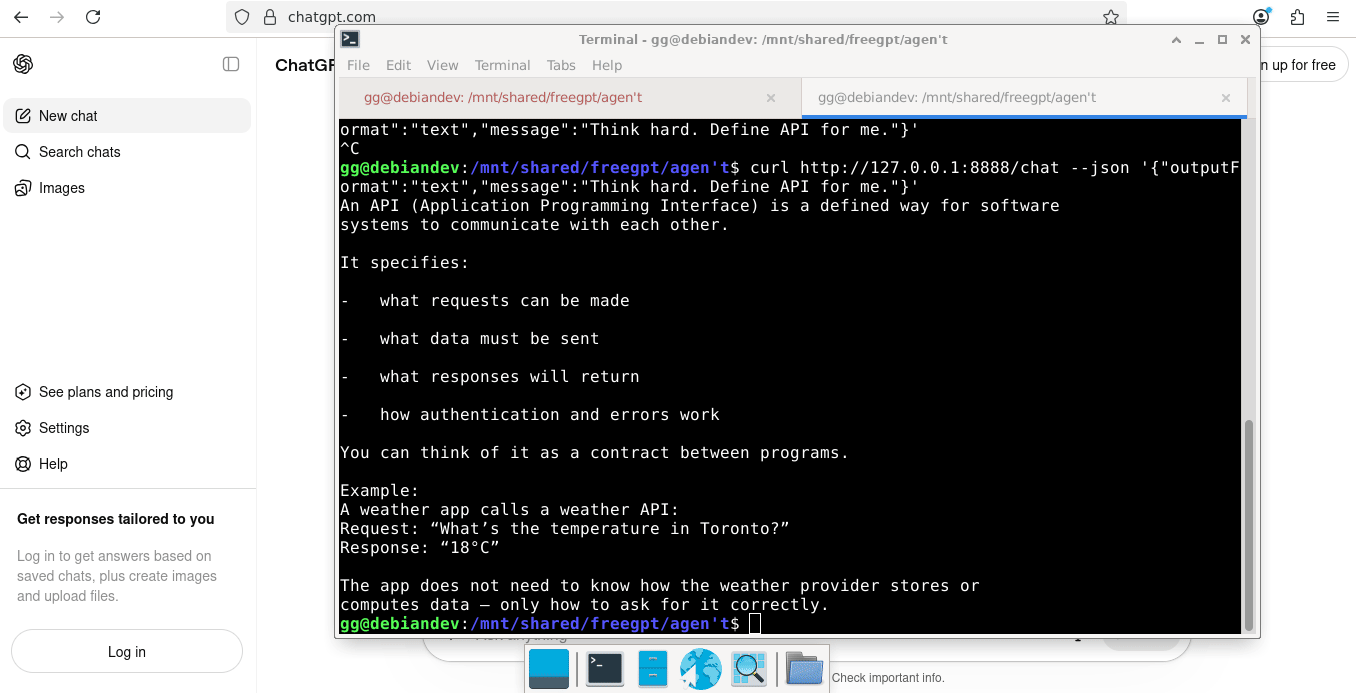
This version was used to make a couple of proof-of-concept neovim plugins. The way I got ChatGPT to generate different output formats is pretty hacky- amounting to just asking it to pretty please change its output to (json|plaintext|markdown), but it worked surprisingly well.
I also added some rudimentary IP rotation via Mullvad VPN by just running a CLI command in the Golang server after each request to avoid rate limits. Similarly, I closed and re-opened Private Firefox instances to wipe cookies away after each request via xdotool.
The delay and resource utilization when automating a whole VM was getting to me a little bit, so I went back to headless browsers, this time exploring the NodeJS(🤮) version of Playwrite. To much more success.
the boring good solution
Patchright is a patched version of NodeJS Playwright that obfuscates the whole thing for you.
In their readme.md they even have a little checkmark saying that it is not detected by Cloudflare…
A bare-bones script like below bypasses Cloudflare:
const { chromium } = require('patchright');
const message = process.argv[2];
(async () => {
const browser = await chromium.launch({
headless: true,
});
const page = await browser.newPage();
await page.goto('https://chatgpt.com');
await page.locator('#prompt-textarea').click();
await page.keyboard.type(message);
await page.keyboard.press('Enter');
try {
const text = await page.locator('.prose.markdown').textContent();
console.log(text);
} catch {
await page.screenshot({ path: 'final.png', fullPage: true });
}
await browser.close();
})();Run it with your message like below, getting the response in stdout.
node scraper.js "What is 10 * 10?"I kept the golang server + bash commands from the previous solution, though this time running it inside a docker container. As a general rule, you probably shouldn’t trust random tools like patchright to run on baremetal. I do not want to catch a bios bug.
I also replaced the xdotool commands and extension with a simple bash command that runs (a beefier version of) the above scraper.js script. Now the flow looks like this:
- Client sends a POST request with message to Golang server in container
- Golang server runs CLI command that runs Patchright scraper.js and outputs response in stdout
- Golang server returns stdout of command to client

Delays are down to less than half of what they previously were for a typical message. Though it’s not nearly as fun without seeing the VM zoom around.
Support for IP rotation (mullvad CLI), output formatting, as well as model selection (Claude, ChatGPT, Gemini, Deepseek) with associated account rotation was added to this version. Since I kept the same interface, it was a drop in replacement for my plugins.
running into bot detection
I did trigger the Cloudflare bot detection captcha a couple of times during testing- but with some minor tweaks like adding random delays, some mouse jitter and using bezier curves for mouse movement, I never got the captcha again. I based my code off of public “humanization” libraries, of which there are quite a few.
Interestingly, I never ran into a captcha using my overengineered solution involving the VM and Firefox extension.
conclusion
I thought it would’ve been harder to do. If I didn’t get nerd-sniped building a distributed system instead of just testing out all of the stealth-oriented headless browser libraries I could’ve built this out in a day.
Though I learned a lot about Manifest V3 browser extensions and Golang along the way.
references
Just basic template code, the Patchright script will likely get detected for non-human movements.